Column-oriented tabular data model (unlike SQLite, like R!)
Very impressive R and Python integration
Easy SQL example to get started
library(duckdb)
data("flights", package = "nycflights13")
con <- dbConnect(duckdb())
duckdb_register(con, "flights", flights)
dbGetQuery(con,
"SELECT origin, COUNT(*) AS n FROM flights GROUP BY origin")
origin n
1 EWR 120835
2 LGA 104662
3 JFK 111279
Easy SQL example to get started
library(duckdb)
data("flights", package = "nycflights13")
con <- dbConnect(duckdb())
duckdb_register(con, "flights", flights)
dbGetQuery(con,
"SELECT origin, COUNT(*) AS n FROM flights GROUP BY origin")
origin n
1 EWR 120835
2 LGA 104662
3 JFK 111279
From easy to merely simple
Name the top 3 destinations for each origin airport.
OK, still easy!
One base R way
Map(function(x) head(names(sort(table(x), decreasing = TRUE)), 3),
split(flights[["dest"]], flights[["origin"]]))
$EWR
[1] "ORD" "BOS" "SFO"
$JFK
[1] "LAX" "SFO" "BOS"
$LGA
[1] "ATL" "ORD" "CLT"
origin dest
1 EWR ORD
2 EWR BOS
3 EWR SFO
4 JFK LAX
5 JFK SFO
6 JFK BOS
7 LGA ATL
8 LGA ORD
9 LGA CLT
SQL (and DuckDB)
dbGetQuery(con,
"SELECT origin, dest
FROM (SELECT origin, dest, n
FROM (SELECT origin, dest, n, RANK() OVER (
PARTITION BY origin ORDER BY n DESC) AS h
FROM (SELECT origin, dest, COUNT(*) AS n
FROM flights
GROUP BY origin, dest
) AS curly
) AS moe
WHERE (h <= 3)
) AS shemp ORDER BY origin;")
origin dest
1 EWR ORD
2 EWR BOS
3 EWR SFO
4 JFK LAX
5 JFK SFO
6 JFK BOS
7 LGA ATL
8 LGA ORD
9 LGA CLT
Simple data manipulation in R (and Python) can be hard in SQL.
The converse is rarely true.
Fortunately, DuckDB works with dplyr!
tbl(con, "flights") %>%
group_by(origin) %>%
count(dest, sort = TRUE, name = "N") %>%
slice_max(order_by = N, n = 3) %>%
select(origin, dest)
origin dest
1 JFK LAX
2 JFK SFO
3 JFK BOS
4 LGA ATL
5 LGA ORD
6 LGA CLT
7 EWR ORD
8 EWR BOS
9 EWR SFO
When and how is a tool like DuckDB really useful?
One way to think about this:
syntax (how), and
performance (when).
Syntax advice
Data manipulation in R is easier than SQL.
Start with R, add dplyr, data.table, etc. as needed.
With dplyr, R works with your database anyway, so one less language to deal with!
Another simple example: "as of" joins
Basic idea:
calendar
date
2020-01-01
2020-02-01
2020-03-01
2020-04-01
2020-05-01
2020-06-01
data
date
value
2019-11-18
0.6870228
2020-01-05
0.0617863
2020-01-10
0.1765568
2020-02-01
0.5000000
2020-02-12
0.2059746
2020-04-13
0.6291140
2020-05-08
0.3841037
‘as of’ desired output
date
value
2020-01-01
0.6870228
2020-02-01
0.5000000
2020-03-01
0.2059746
2020-04-01
0.2059746
2020-05-01
0.6291140
2020-06-01
0.3841037
For each 'calendar' date, find the most recent 'data' value
as of that date.
Many easy ways in R and Python
data[calendar, on = "date", roll = TRUE] # using R data.table
pandas.merge_asof(calendar, data, on = "date") # using Python Pandas
merge(calendar, na.locf(merge(calendar, data)), join = "left") # R xts
(more...)
SQL WITH z AS (
SELECT date, (NULL) AS value FROM calendar
UNION
SELECT date, value FROM data
ORDER BY date
),
a AS (
SELECT date, value, ROW_NUMBER() OVER (
ORDER BY date
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) * (CASE WHEN value IS NULL THEN 0 ELSE 1 END) AS i
FROM z
),
b AS (
SELECT date, MAX(i) OVER (
ORDER BY date
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS j
FROM a
),
c AS (
SELECT b.date, value FROM a, b
WHERE a.i > 0 AND a.i = b.j
),
d AS (
SELECT calendar.date, value FROM calendar, c
WHERE calendar.date = c.date
ORDER BY c.date
)
SELECT * FROM d UNION SELECT * FROM d ORDER BY date
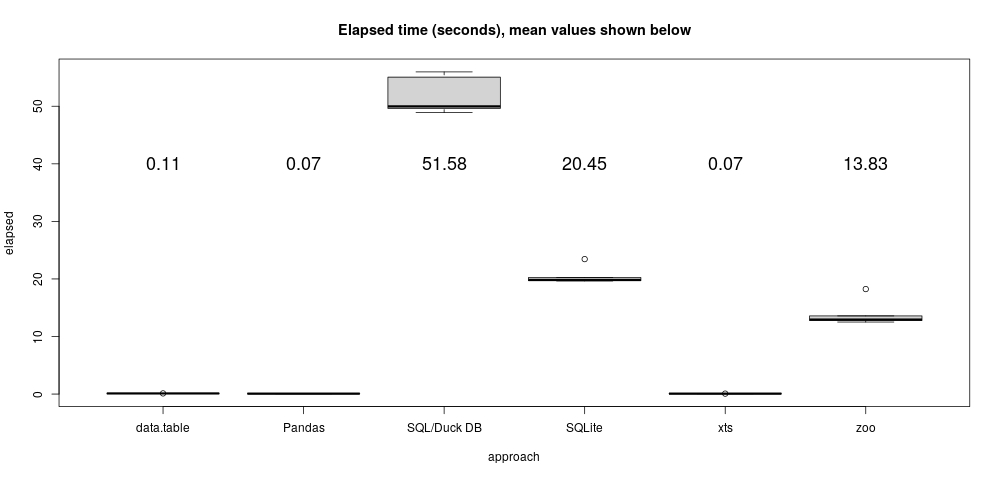
How about performance of that "as of" join on my laptop?
It's a small example: about 5 million data rows, 250K calendar rows!
Performance advice
R outperforms DuckDB for in-memory problems.
DuckDB's advantage is that queries can work without modification on larger-than-RAM data.
Use databases for problems that don't easily fit in RAM.
And when you do, use them with dplyr!
Except...
Larger-than-memory one off problems may run fastest with Jim Hester's
vroom package.